AI generated art and/or images can be impressive. But the systems are definitely not yet ready for prime time.
Admittedly, I may have a way to go in learning the art and craft of "prompt engineering." (Just saying that indicates a problem with the image generation systems. If you have to put enormous effort into learning *how* to get the systems to generate acceptable images, then how does that support the contention that genAI/LLMs are a great tool that will make our lives better and easier?) Herewith are some observations and comments on my forays, so far, into the genAI image creation systems. (Some experiments and observations on the text systems can be found here, here, here, here, and here.)
About a year and a half ago, I tried out a little joke that I called Gnomaste. That was on DALL-E (now called OpenArt). So, I decided to see how much the technology had improved:


Now, these aren't too bad, if you are willing to overlook some minor details. But when I started to ask for more complex images, things got weirder.
Yes, I have to admit that I have strange ideas. But, when I tried to get the earth and the moon colliding, the systems couldn't even get near it: This is Meta AI, which won the first round, and, yes, you can see an earth and a moon included, but nothing indicating a collision. OpenArt and Qwen didn't do any better:
This is Meta AI, which won the first round, and, yes, you can see an earth and a moon included, but nothing indicating a collision. OpenArt and Qwen didn't do any better: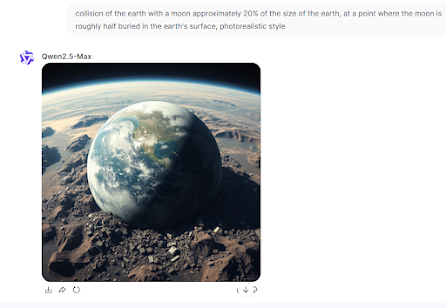




I have always liked the Norris "It's only money" cartoon, so I thought I'd try a tribute. I asked if to add the caption, and found (and later confirmed) the OpenArt won't do that at all: But, even absent the refusal to do any captions, 1) I asked for two figures: where did the third come from? 2) OK, I asked for emaciated, but, skeletal? 3) OK, skeletal makes it hard to show facial expressions (with no faces), but they aren't even *looking* at the chest!
But, even absent the refusal to do any captions, 1) I asked for two figures: where did the third come from? 2) OK, I asked for emaciated, but, skeletal? 3) OK, skeletal makes it hard to show facial expressions (with no faces), but they aren't even *looking* at the chest!

Meta AI wasn't *too* bad: but Qwen gave me the first indication of what *I* consider a serious problem:
but Qwen gave me the first indication of what *I* consider a serious problem: asking for text to be incorporated *really* throws the systems into a tizzy!
asking for text to be incorporated *really* throws the systems into a tizzy!


When I asked for another joke, with only simple text, Meta AI *did* come through: although "ornate" seemed to translate into "South Asian." But both OpenArt and Qwen had problems even with text this simple:
although "ornate" seemed to translate into "South Asian." But both OpenArt and Qwen had problems even with text this simple:




I tried something a little less morbid, and the results were *really* disappointing. (Maybe I should just stick to being weird, dressed, and grieving?) I once found a tattered image (which got further degraded by me taking a shot of it with a cellphone) which had a very lovely thought associated with it. So I tried, with all three systems, and with four different variations on prompts, and failed to get anything remotely acceptable. OpenArt, predictably, refused to include a caption. Qwen started bad: and just got worse. Meta AI was the best of a bad lot:
and just got worse. Meta AI was the best of a bad lot:
 but even the *best* of what it produced has serious problems:
but even the *best* of what it produced has serious problems:




So, I asked them to produce an image to kind of illustrate the problem: and even *that* is a horrible mess!
and even *that* is a horrible mess!

OK, yes, adding a caption is not really image generation. And there are fixes, and relatively easy ones. It just seems very strange that "memes," in the social media rather than the original sense, have been so *much* a part of social media and online content, that failing to allow for them is something the AI devotees have never considered ...
And, even *without* captions, sometimes the AIs just can't count: ... and sometimes they can't count *arms* ...
... and sometimes they can't count *arms* ... (Actually, with the caption that I have in mind, this *could* work ...)
(Actually, with the caption that I have in mind, this *could* work ...)


No comments:
Post a Comment